For both doctors and parents, an infant’s cry is difficult to diagnose. Babies cry when they are hungry, exhausted or colicky. But a baby’s cry can also be a signal that more urgent care is required. Last week we announced our lead investment in Ubenwa, a pioneering developer of AI-powered software for the rapid detection of medical anomalies using infant cry sounds (see TechCrunch feature).
Ubenwa is built on a foundation of scientific research developed in close collaboration with pediatric hospital networks in Canada, Nigeria and Brazil. A Mila spinout, the company is advised by AI pioneer Yoshua Bengio who is also an investor. Charles Onu, the CEO & Co-Founder, is an expert in audio signal processing, machine learning, and the infant cry. The Ubenwa team has developed accurate algorithms for cry activity tracking, acoustic biomarker detection and anomaly prediction, turning infant cries into clinically-relevant insights and potential diagnoses.
The sounds we make as humans can be a window to our health. The non-invasive, passive nature of speech as a biomarker makes it amongst the most popular modalities to detect and diagnose medical conditions, especially neurological conditions that have traditionally been difficult to diagnose. Today most startups in the sound-based biomarkers space focus on neurodegenerative diseases such as Alzheimer’s, Parkinson’s, and Depression.
Ubenwa is targeting the pediatric market where the problem is acute and there is tangible demand. In infants, it is very hard to detect signs of deteriorating pathology and make accurate and potentially life-saving diagnoses. Existing methods, if any, are ineffective because diagnosis is invasive, costly, time-consuming, and involves devices designed for adults. Delayed diagnosis may lead to severe, long-lasting effects or fatality. Ubenwa aims to make the infant cry a new standard passive vital sign.
As Yoshua Bengio puts it: “AI is well-suited to deriving insights from the sound signature of an infant cry. Charles Onu’s leading research into identifying biomarkers in cry sounds offers the promise of unlocking our understanding of what’s behind a baby’s cry.”
AI News This Week
-
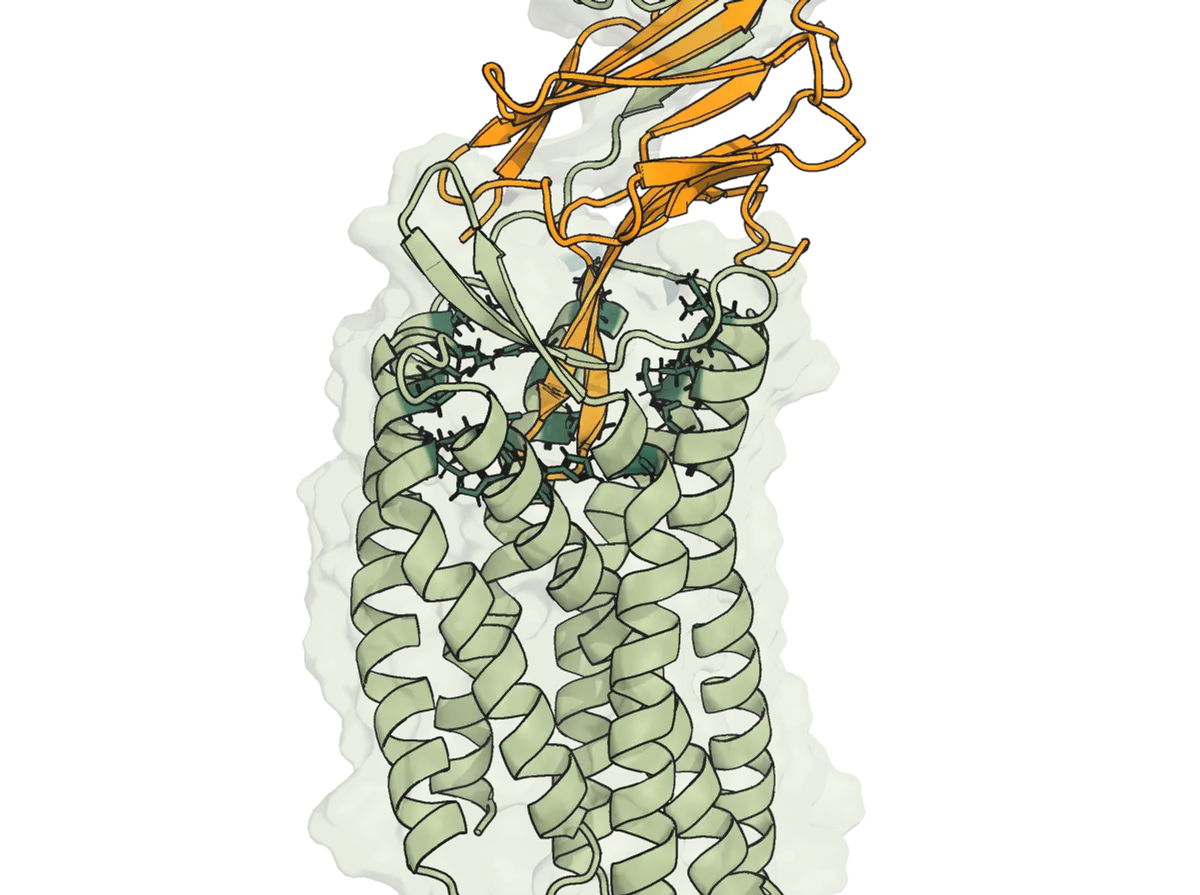
DeepMind has predicted the structure of almost every protein known to science (MIT Technology Review)
When DeepMind introduced AlphaFold in 2020, it took the science community by surprise, using AI to solve one of biology’s ‘grand challenges.’ Last year, DeepMind released the source code of AlphaFold and made the structures of 1 million proteins, including nearly every protein in the human body, available in its AlphaFold Protein Structure Database. The latest data release gives the database a massive boost with 200 million readily available protein structures. Demis Hassabis, DeepMind’s founder and CEO, noted that the update includes structures for “plants, bacteria, animals, and many, many other organisms, opening up huge opportunities for AlphaFold to have impact on important issues such as sustainability, fuel, food insecurity, and understanding and developing therapeutics for neglected diseases.”
-
How Cohere is accelerating language model training with Google Cloud TPUs (Google Cloud)
“Over the past few years, advances in training large language models (LLMs) have moved natural language processing (NLP) from a bleeding-edge technology that few companies could access to a powerful component of many common applications.” A general rule for NLP (which powers our chatbots, content moderation, and search), is that greater accuracy and understanding comes with larger models. Getting this scale has become a major challenge for companies as it requires specialized algorithms, extensive compute, memory, and fast interconnects. In a new technical paper, engineers at Radical portfolio company Cohere demonstrate how their new FAX framework deployed on Google Cloud’s TPU v4 Pods addresses the challenges of scaling LLMs to hundreds of billions of parameters. This framework aims to accelerate the research, development, and production of LLMs with two significant improvements: scalability and rapid prototyping.
-
Pile of Law: Learning responsible data filtering from the law and a 256GB open-source legal dataset (arXiv)
Stanford researchers have built the Pile of Law, “a 256GB (and growing) dataset of open-source English-language legal and administrative data, covering court opinions, contracts, administrative rules, and legislative records” in the US. The dataset is a useful input for pre-training models and serves as a case study for filtering data and privacy – a complex issue many data creators face. The data comes with some built-in filtering because it is based on legal texts which, in many jurisdictions, do not permit the publication of dates of birth and financial or identifying numbers. The researchers note that using similar privacy filtering rules in pre-training models “would already go beyond much of current modeling practice.”
-
Policy: United Kingdom sets out proposals for new AI rulebook (GOV.UK)
The United Kingdom released plans for AI regulation that reject the European Union’s centralized approach to date. Oversight in the UK will be given to existing regulators whose rules will be sector-dependent rather than having a single regulator. The EU is often seen as steering global technology standards, most notably proposing the AI Act as the world’s first major legislative package. The AI rulebook aligns the UK with the United States’ approach based on guidance rather than hard regulation (at least at the federal level). Similar to Canada’s guiding principles for effective and ethical use of AI in government, the UK government wants its regulators to follow six principles when devising AI rules. A white paper will be released in late 2022 setting out further details.
-
The AI platform behind a Bezos-backed startup’s vegan burgers (Bloomberg)
Plant-based milk and burgers often use sunflower oil as a key component. The war in Ukraine continues to disrupt supplies. Applying AI to the problem has helped one company adapt their recipes. The AI platform was previously used to tweak recipes to cope with a shortage of pea protein, an ingredient in some plant-based milk brands. The platform uses a database to produce a formula for plant-based versions of animal products while considering flavour, texture, colour, and nutritional value.
Radical Reads is edited by Ebin Tomy (Analyst, Radical Ventures)