Editor’s note:
Large language models (LLMs) are predicted to play an ever larger role for businesses across every industry in 2022. With that in mind, we invited Aidan Gomez, the CEO and co-founder of Radical portfolio company Cohere and a co-inventor of Transformers, and Jay Alammar, Partner Engineer at Cohere, to provide an introduction to LLMs. Cohere lets any business leverage world-leading natural language processing technology through a simple API.
Language is important. It’s how we learn about the world (e.g. news, searching the web or Wikipedia), and also how we shape it (e.g. agreements, laws, or messages). Language is also how we connect and communicate — as people, and as groups and companies.
Despite the rapid evolution of software, computers remain limited in their ability to deal with language. Software is great at searching for exact matches in text, but often fails at more advanced uses of language — ones that humans employ on a daily basis. There’s a clear need for more intelligent tools that better understand language.
A recent breakthrough in artificial intelligence is the introduction of language processing technologies using Transformers, that enable us to build more intelligent systems with a richer understanding of language than ever before. Large pretrained language models vastly extend the capabilities of what systems are able to do with text.

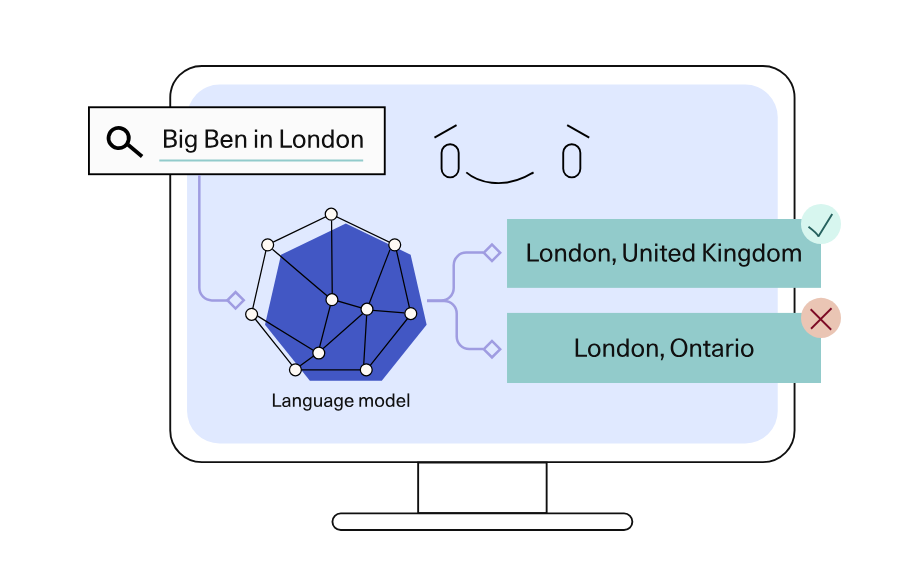
Here are a few examples of language understanding systems that can be built on top of large language models.
Large language models present a breakthrough in text generation. For the first time in history, we have software programs that can write text that feels like it’s written by humans. These capabilities open doors to use cases like summarization or paraphrasing.
Language models can be instructed to generate useful summaries or paraphrases of input text by guiding them using a task description in the prompt.
Classification is one of the most common use cases in language processing. Building systems on top of language models can automate language-based tasks and save time and effort. Developers can build classifiers on top of Cohere’s language models. These classifiers can automate language tasks and workflows.
Think of how many repeated questions have to be answered by a customer service agent every day. Language models are capable of judging text similarity and determining if an incoming question is similar to questions already answered in the FAQ section. There are multiple things a system can do once it receives the similarity scores — one possible next action is to simply show the answer to the most similar question (if above a certain similarity threshold). Another possible next action is to make that suggestion to a customer service agent.
Unlocking NLP
Adding language models to empower Google Search was noted as “representing the biggest leap forward in the past five years, and one of the biggest leaps forward in the history of Search.” Microsoft also uses such models for every query in the Bing search engine.
Despite the utility of these models, training and deploying them effectively is resource-intensive in its requirements of data, compute, and engineering resources.
Cohere offers an API to add cutting-edge language processing to any system. Cohere trains massive language models and puts them behind a simple API. Moreover, through finetuning, users can create massive models customized to their use case and trained on their data. This way, Cohere handles the complexities of collecting massive amounts of text data, improving ever-evolving neural network architectures, distributed training, serving models around the clock, and hiding all that complexity behind a simple API available to everyone, including for companies without the internal technical teams and resources or computing power of Google or Microsoft.
AI News This Week
-
Robotic arms are using machine learning to reach deeper into distribution (Wall Street Journal)
As industrial robots become more functional, they are also becoming smarter. AI is enabling robots to see, reason, and act on the world around them. The Wall Street Journal reported on this evolution, describing how Connecticut-based GXO Logistics Inc. uses a robotic arm equipped with camera vision to help speed up the order fulfillment process. The system, developed by logistics-automation company Knapp AG and run by Radical portfolio company Covariant, augments manual picking processes.
-
BioNTech and InstaDeep develop AI-based “early warning system” for COVID-19 variants (Fortune)
Flagging potential high-risk variants early could alert researchers, vaccine developers, health authorities, and policymakers, and change the trajectory of new variants. BioNTech, the German biotech company that pioneered the messenger RNA technology behind the Pfizer COVID-19 vaccine, has teamed up with London-based AI company InstaDeep to create what the firms say is an effective early warning system for spotting potentially dangerous new coronavirus variants. The first part of the system predicts the structure of a variant’s spike protein from the DNA sequence. The second takes the DNA sequence and treats it as a language using AI techniques that have been developed for NLP to examine how similar the DNA sequence for a particular variant’s spike protein is to other known coronavirus spike proteins. From this, the researchers derive two additional scores to assist with ranking variants on their risk factors.
-
Eliciting Latent Knowledge – The First ARC Report (AI Alignment Forum)
The Alignment Research Centre (ARC) is an AI safety organization founded in 2021 by Paul Christiano (formerly of OpenAI). Their first report has been released on the topic of “eliciting latent knowledge” (ELK) and it tackles the problem of building AI systems that we can trust, even if the system is much more complicated than what a human can understand. ARC is first focusing on developing an “end-to-end” alignment strategy (aligning machine learning systems with human interests) that could be adopted in industry today.
-
Dark Energy Spectroscopic Instrument creates largest 3D map of the cosmos (Phys.org)
The Dark Energy Spectroscopic Instrument (DESI) is in the process of creating the largest three-dimensional map of the universe. DESI is an international science collaboration managed by the Berkeley Lab. The survey has already cataloged over 7.5 million galaxies and is adding more at a rate of over a million a month. By the end of its run in 2026, DESI is expected to have over 35 million galaxies in its catalog, enabling an enormous variety of cosmology and astrophysics research. Scientists note that “all this data is just there, and it’s just waiting to be analyzed.” AI is increasingly being used by scientists for galaxy discovery and to help analyze the massive datasets in this field.
-
NFL taps data scientists for new ways to automatically detect players’ helmet impacts (NFL)
The NFL continues to tap data scientists to help track impacts during the game as part of their safety efforts. The tedious task of tracking every helmet collision, especially along the line of scrimmage, makes it difficult to do more than just a small sampling of games as the league tries to gather more data on head impacts. For the second year, the NFL has run a competition focused on creating an AI model that would detect impacts from game footage and identify the specific players involved in those impacts. Interestingly, in both years the winner has come from outside of the US with Japanese data scientist Kippei Matsuda taking the prize in 2021 and Australian data scientist Dmytro Poplavskiy winning in 2020.
Radical Reads is edited by Ebin Tomy.