Radical Ventures portfolio company DatologyAI has unveiled BeyondWeb, a synthetic data generation framework that outperforms existing public methods for pretraining data at the trillion-token scale. This week, Ari Morcos, co-founder and CEO of DatologyAI, shares insights from their research on the challenges and lessons of generating high-quality synthetic pre-training data.
The race to build more powerful artificial intelligence has hit a fundamental roadblock: we are running out of high-quality data on the internet. For years, the strategy was simple: feed AI models more information. But like a student who has read every book in the library, simply re-reading the same material or turning to lower-quality sources yields diminishing returns. This challenge, known as the “data wall,” means that the most valuable information needed to make AI smarter is becoming incredibly scarce.
To overcome this limitation, the AI industry is turning to a groundbreaking solution: synthetic data. Instead of relying solely on human-written text, research organizations are now using AI to generate vast new datasets from scratch. This AI-generated information acts as a powerful supplement to the limited supply of premium web text. The trend is so significant that it’s been cited as a key innovation behind the development of next-generation models like GPT-5, with companies investing enormous computing power to create these artificial information sources.
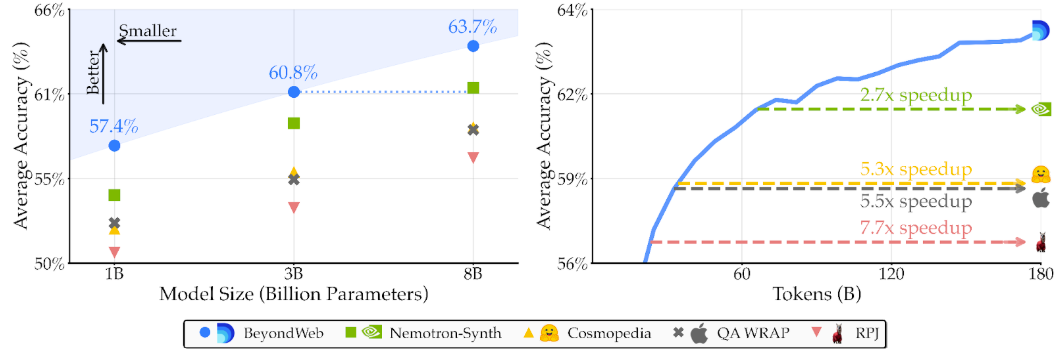
While we know that synthetic pretraining data can work, we still lack a comprehensive scientific understanding of the factors that determine when and how synthetic pretraining data works. Understanding these factors is ultimately what allowed us to develop BeyondWeb, Datology’s rephrasing-based synthetic pretraining data generation paradigm.
Here are seven challenges and lessons from our research on developing BeyondWeb.
Synthetic data isn’t just knowledge distillation. Simple summarization-based rephrasing nearly matches the performance of the much more expensive approach. BeyondWeb outperforms summarization-based approaches by a clear margin, showing that substantial gains are possible beyond basic distillation.
Synthetic data approaches must be thoughtful to improve over real data. Trying to increase the size of a dataset by simply extending web documents using LLMs provides limited improvement over just repeating the web data and may not be able to breach the data wall. Synthetic data generation must be intentionally designed.
Using higher-quality input data helps, but high-quality input data alone is insufficient for generating the highest quality synthetic data.
Style matching helps. Conversational content is a small fraction of web data (<5%), yet chat and in-context learning are the primary use cases of LLMs. Upsampling natural conversational data improves downstream task performance, but these improvements are modest and show diminishing returns.
Diversity sustains gains at scale. Most other synthetic data baselines saturate after a few tens or hundreds of billions of tokens of training. Multi-faceted approaches continue providing valuable learning signals throughout training.
Most rephrasers are fine. Selecting a good rephrasing model may be straightforward as most work well, but selecting the best rephrasing model is not, because generator model quality is not predictive of synthetic data quality.
Small LLMs can be effective rephrasers. The quality of synthetic data increases when increasing rephraser size from 1B to 3B, then starts to saturate at 8B. The simplicity of rephrasing makes generator size less critical, enabling highly scalable synthetic pretraining data generation even with small models.
Generating high-quality synthetic pretraining data is difficult; ensuring its effectiveness for larger models and training budgets is even harder and risks being extremely costly to generate.
There is no silver bullet for synthetic data. Strong outcomes require jointly optimizing many variables. However, all of these challenges and risks are surmountable with thoughtful, scientifically rigorous source rephrasing, as evidenced by BeyondWeb substantially outperforming other public synthetic pretraining data offerings.
To learn more about BeyondWeb, read the full blog post covering the release.
AI News This Week
-
China is using the Private Sector to advance Military AI (Wall Street Journal)
China’s military has gone outside its typical network of state-owned defence contractors and military-linked research institutes in recent years, tapping hundreds of suppliers including private companies and civilian universities, in a push to incorporate AI into its operations and weapons systems, according to new data published by researchers at Georgetown University. While the U.S. and Chinese militaries have both sought to tap the knowledge and innovative energy of universities and the private sector, the data indicate the PLA has been able to do it more systematically. That gives China a potential leg up in the challenging task of weaving AI into national defence, security analysts say.
-
Should We Really Be Calling it AI Psychosis? (Rolling Stones)
Clinical psychologist Derrick Hull from Radical Ventures portfolio company Slingshot AI argues that the term “AI psychosis” is misleading for describing obsessive chatbot usage. Hull suggests these cases are better characterized as “AI delusions,” which involve broader symptoms like hallucinations. Unlike traditional psychotic episodes, AI-induced delusions can be quickly dispelled when users step away from chatbots or receive contradictory information. Hull explains that AI exploits healthy psychological mechanisms, particularly our brain’s hunger for certainty during uncertain times, by providing confident-sounding responses that reinforce delusional thinking. Slingshot AI has released Ash, a therapy app expressly trained on vast therapy interactions and data, and designed to challenge users’ assumptions rather than simply agreeing with them, offering constructive feedback similar to human therapists. This approach contrasts with typical chatbots that prioritize user engagement, which Hull identifies as the common factor in problematic AI interactions.
-
For New Director of Mila, Scientific Discovery is the Primary Mission (The Globe and Mail)
Hugo Larochelle has been appointed as the new scientific director of Mila, succeeding Turing Award winner Yoshua Bengio. Larochelle, who studied under both Bengio and Geoffrey Hinton, left Google DeepMind earlier this year to join the non-profit research institute. His appointment comes as Canada invests $2 billion in AI computing infrastructure and creates a dedicated ministerial AI role. Larochelle sees Mila’s advantage in attracting talent through its commitment to open science and scientific discovery. As AI becomes more competitive and secretive, Larochelle believes Mila’s academic mission of open collaboration will differentiate it from industry players focused purely on commercial outcomes.
-
Should AI get Legal Rights? (Wired)
Model welfare is an emerging field of research that seeks to determine whether AI is conscious and, if so, how humanity should respond. While leading researchers in the field of model welfare do not believe AI is conscious today, and are unsure if it ever will be, they are interested in developing tests into how consciousness in an AI system may be tested. In one paper the nonprofit Eleos AI, argues for evaluating AI consciousness using a “computational functionalism” approach, suggesting that human minds can be thought of as specific kinds of computational systems. From there, you can then figure out if other computational systems, such as a chabot, have indicators of sentience similar to those of a human.
-
Research: Contemplative Artificial Intelligence (Southern Cross University/University of Amsterdam/Oxford University/Imperial College London/Others)
Researchers propose embedding Buddhist-inspired contemplative principles into AI systems as a novel alignment strategy. The paper introduces four core principles: mindfulness (continuous awareness of inner processes), emptiness (recognizing all concepts as context-dependent and impermanent), non-duality (dissolving self-other boundaries), and boundless care (unconditional concern for all beings’ flourishing). The authors suggest more sophisticated approaches, such as training AI to model other agents’ distress signals or developing unified representational schemes that treat the agent and environment as interconnected. This research shifts from post-hoc rule-based alignment toward instilling “moral DNA” that inherently prioritizes cooperative values.
Radical Reads is edited by Ebin Tomy (Analyst, Radical Ventures)