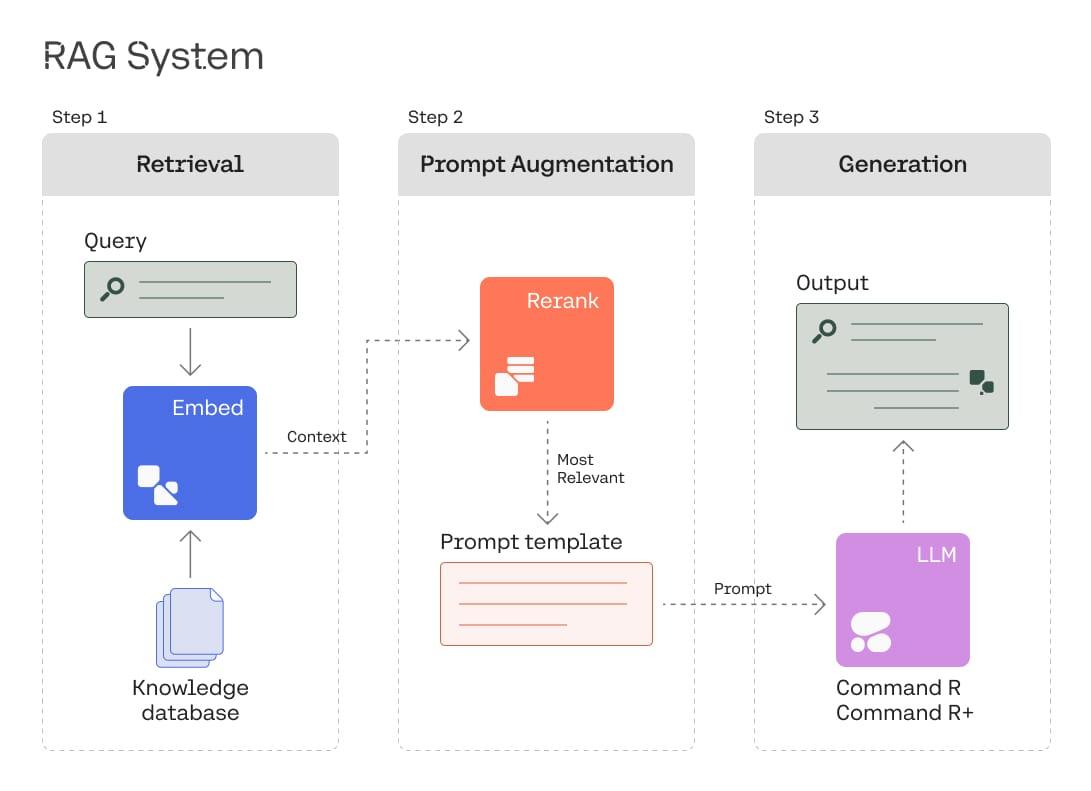
As enterprises integrate large language models (LLMs) into their workflows, they often face challenges related to reliability and erroneous outputs. Cohere, a Radical Ventures portfolio company, is at the forefront of tackling these issues through its development of Retrieval-Augmented Generation (RAG) systems. In a seminal paper, Cohere’s Patrick Lewis described RAG as a method that enhances generative models by integrating them with accurate, up-to-date data from external sources. This integration is essential, as LLMs alone may lack access to the most recent or specific data needed for certain queries.
The RAG process involves three steps: initially, it retrieves relevant data (retrieval), then it augments the original query with this data to create a more effective prompt (prompt augmentation), and finally, it uses this prompt to generate a more accurate and relevant response (generation).
Praised for its adaptability, scalability, and transparency, RAG is becoming increasingly valuable to enterprises seeking precise and dependable AI solutions. This week, we highlight Cohere’s role in advancing RAG technology by featuring an excerpt from their blog, demonstrating its growing importance in enhancing the functionality and reliability of AI initiatives.
Creating Value from RAG Systems
There are five primary reasons that companies are choosing to build LLM solutions using RAG pipelines:
- Reduced hallucination and increased trust.
LLMs can sometimes generate incorrect or nonsensical outputs, known as “hallucinations,” when they lack the required knowledge. By providing relevant external data, RAG mitigates hallucinations and increases user trust in the LLM’s outputs, which are grounded in verifiable information sources. This is particularly true when testing for factual accuracy in domain-specific queries.
- Improved accuracy and relevance of responses.
RAG allows LLMs to access and incorporate up-to-date, domain-specific information from external data sources like databases, documents, and knowledge bases. This enhances the accuracy and relevance of LLM outputs by grounding them in factual, contextual data rather than just the model’s training data which can be outdated or lack specialized knowledge – in some cases improving results by as much as 50%.
- Ability to customize and personalize end solutions.
RAG allows businesses to customize LLM solutions by incorporating their proprietary data from internal knowledge bases, customer records, and other private information sources, including their CRMs and ERP solutions. This enables highly personalized and context-aware responses tailored to the specific business domain, products, services, and customer needs. For example, IBM is currently using RAG to ground its internal customer-care chatbots on content that can be verified and trusted.
- Scalability and adaptability.
Instead of retraining or fine-tuning an entire LLM, RAG allows businesses to update and expand the external knowledge sources as needed. This makes it easier and more cost-effective to keep LLM solutions up-to-date with the latest information and adapt to changing business requirements. For enterprises looking for cross-functional solutions that take advantage of existing datastores, an LLM trained with RAG capabilities, like Cohere Command R / R+, can be applied to multiple domains by switching the retrieval data sources, thus avoiding repetitive fine-tuning costs.
- Auditability and transparency.
Some LLMs can provide citations when using a RAG system. Ideally, you’ll want to use a model specifically trained to generate accurate citations, like Command R / R+. These citations refer back to the external data sources used to generate and augment a response with RAG. While this does not completely solve the problem of hallucinations, the additional transparency improves auditability, explainability, and trust in the LLM’s outputs, especially in regulated industries or high-stakes decision-making scenarios. Without proper citations, LLM outputs could potentially violate intellectual property rights or spread misinformation. Providing clear attributions to sources reduces legal risks and liabilities associated with the misuse or misrepresentation of information. This is especially relevant in regulated industries where there are strict compliance requirements around information handling. Our latest models Command R / R+ are trained to provide highly-accurate in-line citations for all RAG solutions.
By leveraging RAG, businesses can enhance the scope of capabilities of their LLM solutions, delivering more accurate, relevant, and trustworthy outputs while maintaining control over the information sources and enabling customization to their specific needs and domains. It is no wonder that Enterprise AI builders are choosing RAG systems to handle the diversity and complexity of their LLM solutions.
AI News This Week
-
Nvidia’s latest investment is an AI startup focusing on video search (Bloomberg)
Twelve Labs, a Radical Ventures portfolio company, secured $50 million in Series A funding co-led by Nvidia and New Enterprise Associates (NEA). Twelve Labs has developed multimodal AI models that can retrieve specific moments from extensive video archives. Founded in 2021, Twelve Labs aims to revolutionize video search and analysis using AI. Multimodal AI models like those developed by Twelve Labs are poised to master the complexity of video data, which constitutes 80% of the world’s data, in the same way that large language models have mastered natural language.
-
Can satellites combat wildfires? Inside the booming 'space race' to fight the flames (LA Times)
Muon Space, a Radical Ventures portfolio company, is at the forefront of enhancing wildfire management through its role in the Earth Fire Alliance’s FireSat project. This initiative involves a network of over 50 satellites equipped with advanced multispectral infrared instruments, designed to monitor wildfires globally. These satellites will provide detailed data every 20 minutes, improving the detection, monitoring, and management of wildfires. The first three satellites are set to launch by 2026, significantly advancing the use of space-based technologies in environmental protection.
-
Scaling neural machine translation to 200 languages (Nature)
The No Language Left Behind (NLLB) initiative at Meta AI is working to advance neural machine translation to encompass 200 languages, prioritizing low-resource languages typically overlooked by existing technologies. NLLB joins other initiatives pushing the scope of multilingual AI including Cohere For AI’s project Aya, spanning three models and 3,000 researchers across 119 countries. These initiatives highlight the critical role of community engagement in fostering innovation and preserving linguistic diversity and cultural heritage within technology.
-
How will AI be regulated? (Financial Times)
The EU’s new AI Act, which starts in 2025, will mitigate high-risk AI applications and make companies liable for the effects of large, general-purpose AI systems. The Act includes requirements for transparency, risk assessment, and incident reporting, particularly targeting high-risk applications like job or loan decisions. Critics argue that the regulation may be pre-mature and could stifle innovation. In contrast, the US is adopting a more flexible approach, with existing regulatory bodies like the FTC investigating AI applications. The private sector is also calling for regulation to avoid past mistakes seen with social media.
-
Research: Perplexity-Based Data Pruning With Small Reference Models (Databricks/MIT/DatologyAI)
Researchers from Databricks, MIT, and Radical Ventures portfolio company DatologyAI have developed a new data pruning technique using small language models to boost the performance of larger ones. This method utilizes perplexity – a measure of a model’s predictive accuracy – to efficiently prune large text datasets. The approach involves training a smaller model (125 million parameters) on a data subset, assessing each sample’s perplexity, and keeping only the lowest-perplexity samples for training larger models. This technique enhanced task performance by over 2% and reduced pre-training steps, demonstrating its efficacy in managing and refining large-scale datasets for optimal training outcomes.
Radical Reads is edited by Ebin Tomy (Analyst, Radical Ventures)