AI inference is rapidly becoming one of the largest computing markets in history. Training built AI’s foundation, but inference will define the economics of the next decade. Yet, a paradox remains. We have technology that can democratize expert healthcare, education, and research, but a tiny fraction of one percent of the global population uses the pro plans of frontier models.
The bottleneck is physical. We are out of power, memory, and wafers, while actual demand sits orders of magnitude higher. Breaking this gridlock requires a radical hardware breakthrough and no company is better positioned to deliver it than Etched.

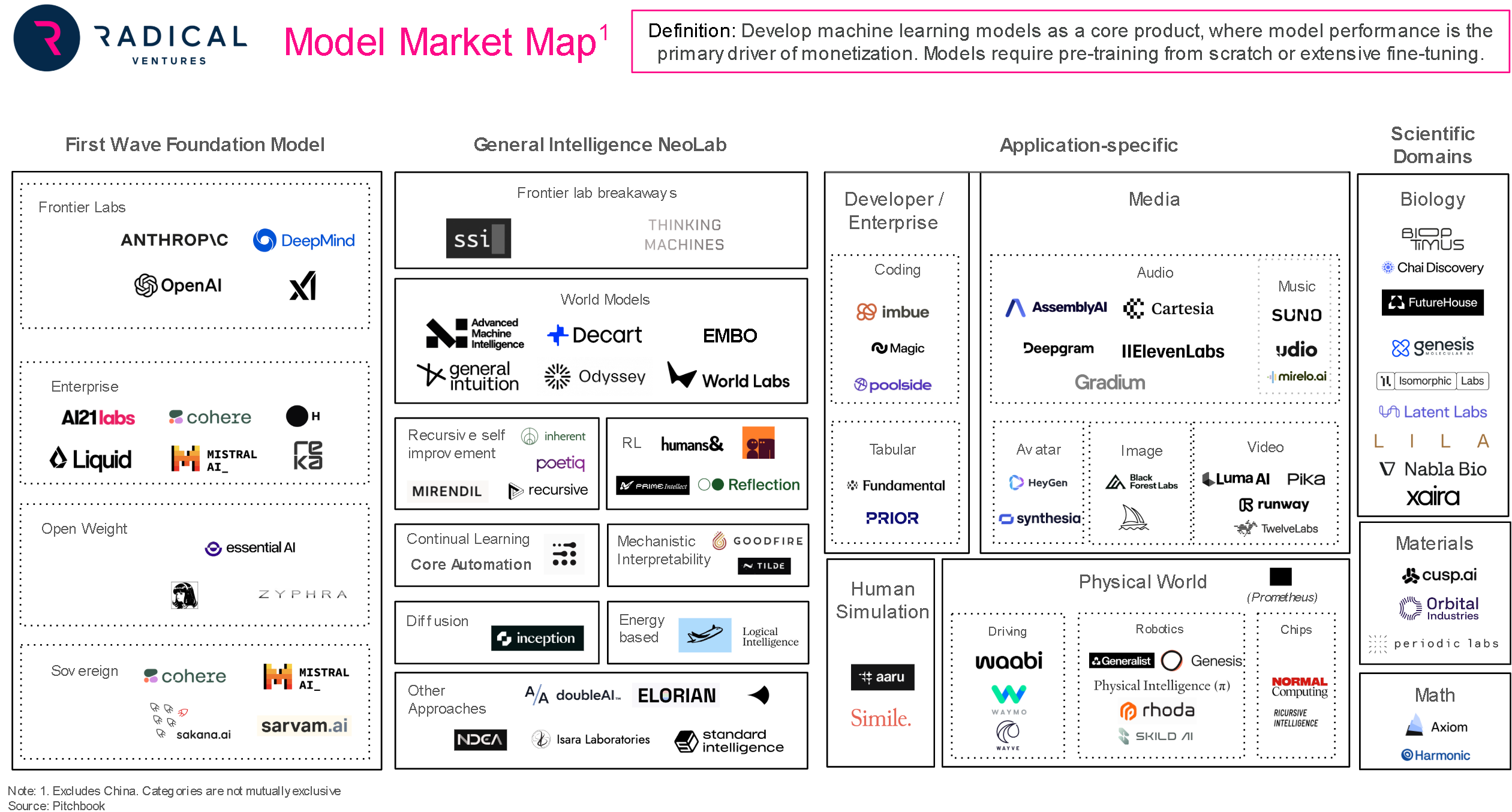
The Inference Paradigm and the Market Landscape
Gartner predicts that more than 80% of all data center workload accelerators will be dedicated to inference. Current hardware is not optimized for this demand, creating an acute economic bottleneck: critical everyday development applications like Cursor, ChatGPT, and Replit are often forced to run at negative gross margins due to the punishing costs of model inference.
The inference landscape is divided between general-purpose processors built for structural generality and early ASIC players, whose memory architecture increases the total cost of ownership under many common workloads. Within the emerging next-gen startups, MatX and Fractile remain a long way from delivering hardware to the market. Conversely, Etched is now in production moving swiftly to service a massive customer pipeline that delivers unprecedented throughput and latency advantages over the established incumbents.
Cracking the Memory Wall
In generative AI inference workloads, hardware architectures are constantly bottlenecked by the “Memory Wall,” the structural limitation where data transfer speeds cannot keep pace with compute logic processing capacity.
During the iterative decode phase of Large Language Models and the complex execution loops of autonomous AI agents, memory latency and memory bandwidth become the ultimate constraints. To push out the entire curve for throughput and latency, Etched avoids these scaling compromises by co-designing new interconnects, power delivery, packaging, and manufacturing methods around proprietary core technologies a few of which include:
- Low Voltage Inference (LVI): This architecture enables the highest FLOP density per watt of any processor and delivers world-class throughput on prefill-heavy workloads. It allows Etched to run large models at 80%+ Model Flops Utilization (MFU) while completely avoiding thermal throttling through a novel combination of new math arrays, tiling and scheduling algorithms, power delivery networks, and custom cold plate designs.
- Cluster Scale Memory (CSM): This creates a unified SRAM pool significantly larger than modern GPUs, offering world-class memory bandwidth, interconnect latency, and decode performance. By combining hybrid HBM/SRAM memory subsystems, custom interconnect protocols, and SerDes stacking, Etched builds gigantic, ultra-low-latency scale-up domains. This approach completely avoids the cost, reliability, yield, thermal, and compute tradeoffs plaguing SRAM-only and 3D DRAM architectures.
Our investment in Etched is anchored by immense commercial demand, disruptive economics, and the team’s incredible velocity. Co-founders Gavin Uberti and Robert Wachen have scaled the Etched team from 20 to 400+ engineers in under three years, pulling elite veterans from Nvidia, Google, Broadcom, and SK Hynix. Fueled by this relentless execution, Etched has charted the fastest path to gigawatt-scale production of any AI hardware startup in history. We are proud to partner with Gavin and Rob as they build the next generation of global AI infrastructure.
Radical Reads is edited by Ebin Tomy (Analyst, Radical Ventures)